Robodesk

Model-based reinforcement learning (MBRL) has gained much attention for its ability to learn complex behaviors in a sample-efficient way: planning actions by generating imaginary trajectories with predicted rewards. Despite its success, we found surprisingly that reward prediction is often a bottleneck of MBRL, especially for sparse rewards that are challenging (or even ambiguous) to predict. Motivated by the intuition that humans can learn from rough reward estimates, we propose a simple yet effective reward smoothing approach, DreamSmooth, which learns to predict a temporally-smoothed reward, instead of the exact reward at the given timestep. We empirically show that DreamSmooth achieves state-of-the-art performance on long-horizon sparse-reward tasks both in sample efficiency and final performance without losing performance on common benchmarks, such as Deepmind Control Suite and Atari benchmarks.
State-of-the-art MBRL algorithms like DreamerV3 and TD-MPC use reward models to predict the rewards that an agent would have obtained for some imagined trajectory. The predicted rewards are vital because they are used to derive a policy — overestimating reward causes the agent to choose actions that perform poorly in reality, and underestimating will lead an agent to ignore high rewards.
We find that in many sparse-reward environments, especially those with partial observability or stochastic rewards, reward prediction is surprisingly challenging. Specifically, the squared-error loss function used in many algorithms require reward models to predict sparse rewards at the exact timestep, which is difficult in many environments, even for humans. In such cases, predicting a sparse reward even one timestep too early or too late incurs a large loss, more than simply predicting no reward at all timesteps.
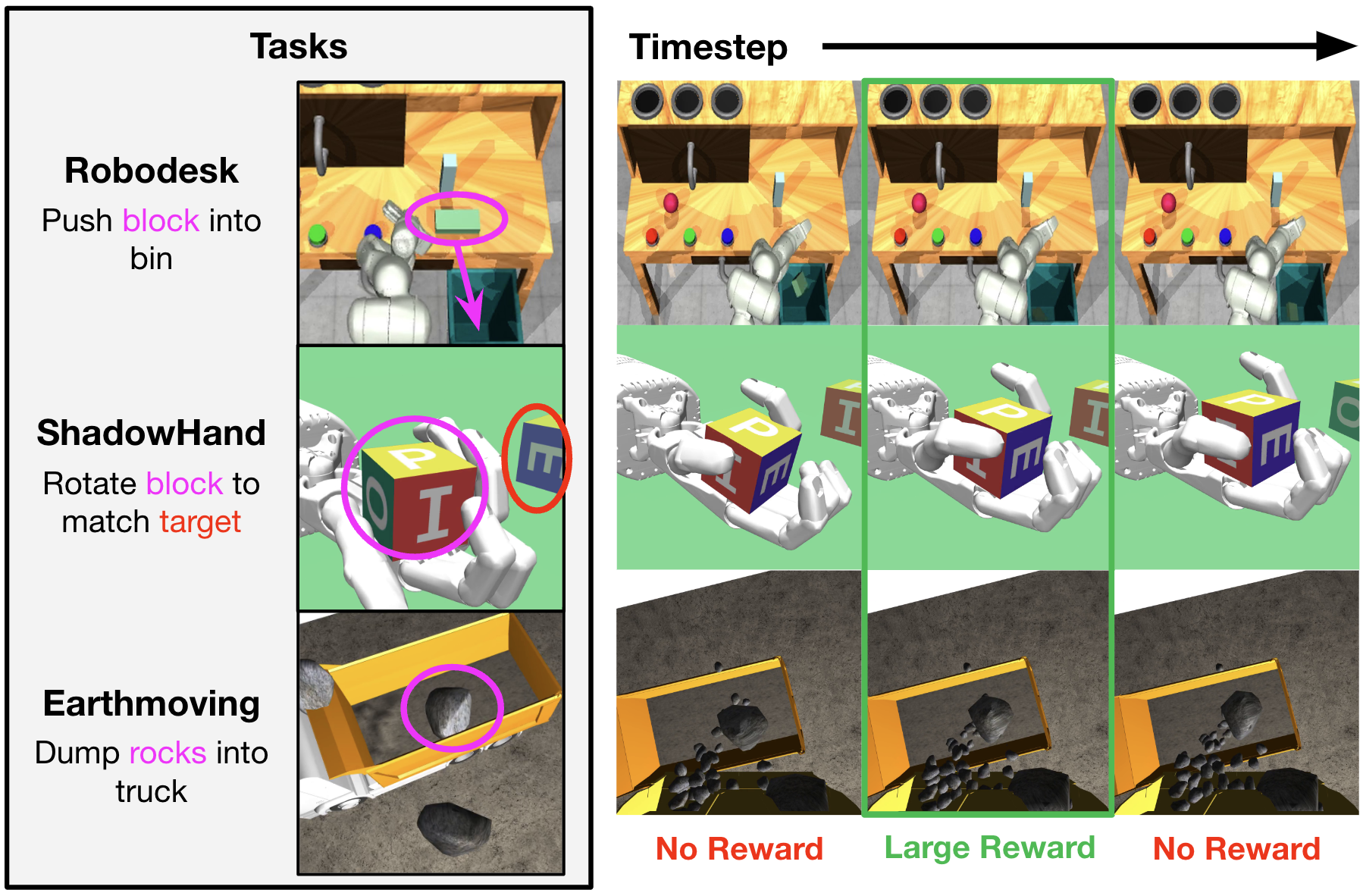
The model therefore minimizes loss by frequently omitting sparse rewards from its predictions. We observe this in several environments - the following are plots, in each environment, of predicted and ground truth rewards over a single episode, for a trained DreamerV3 agent. The sparse rewards omitted by the reward model are highlighted in yellow.




Notice that in all 4 environments, the reward model predicts 0 reward even when the agent completes the task successfully.
We propose DreamSmooth, which performs temporal smoothing of the rewards obtained in each rollout before adding them to the replay buffer. By allowing the reward model to predict rewards that are off from the ground truth by a few timesteps without incurring large losses, our method makes learning easier, especially when rewards are ambiguous or sparse.
Our method is extremely simple, requiring only several lines of code changes to existing algorithms, while incurring minimal overhead.
In this work, we investigate three popular smoothing functions: Gaussian, uniform, and exponential moving average (EMA) smoothing. The plots below illustrate the effect of these functions on reward signals for various values of smoothing parameters.



We find that our method makes reward prediction much easier. On many tasks, DreamSmooth is able to predict sparse rewards much more accurately than vanilla DreamerV3, which we use as our base algorithm. The following plots show predicted, smoothed, and ground truth rewards over the course of a single episode in various envionments.





More importantly, the improved reward predictions of DreamSmooth translates to better performance. Our method outperforms DreamerV3 on many sparse-reward environments, achieving a task completion rate up to 3x higher in a modified Robodesk environment.





A notable exception is Crafter, where DreamSmooth, despite producing more accurate reward predictions, tends to perform worse than DreamerV3.
We find that reward smoothing can also improve the performance of TD-MPC, allowing the algorithm to solve the Hand task where it otherwise could not. This suggests that DreamSmooth can be useful in a broad range of MBRL algorithms that use a reward model.


@inproceedings{lee2024dreamsmooth,
author = {Vint Lee and Pieter Abbeel and Youngwoon Lee},
title = {DreamSmooth: Improving Model-based Reinforcement Learning via Reward Smoothing},
booktitle = {The Twelfth International Conference on Learning Representations},
year = {2024},
url = {https://openreview.net/forum?id=GruDNzQ4ux}
}